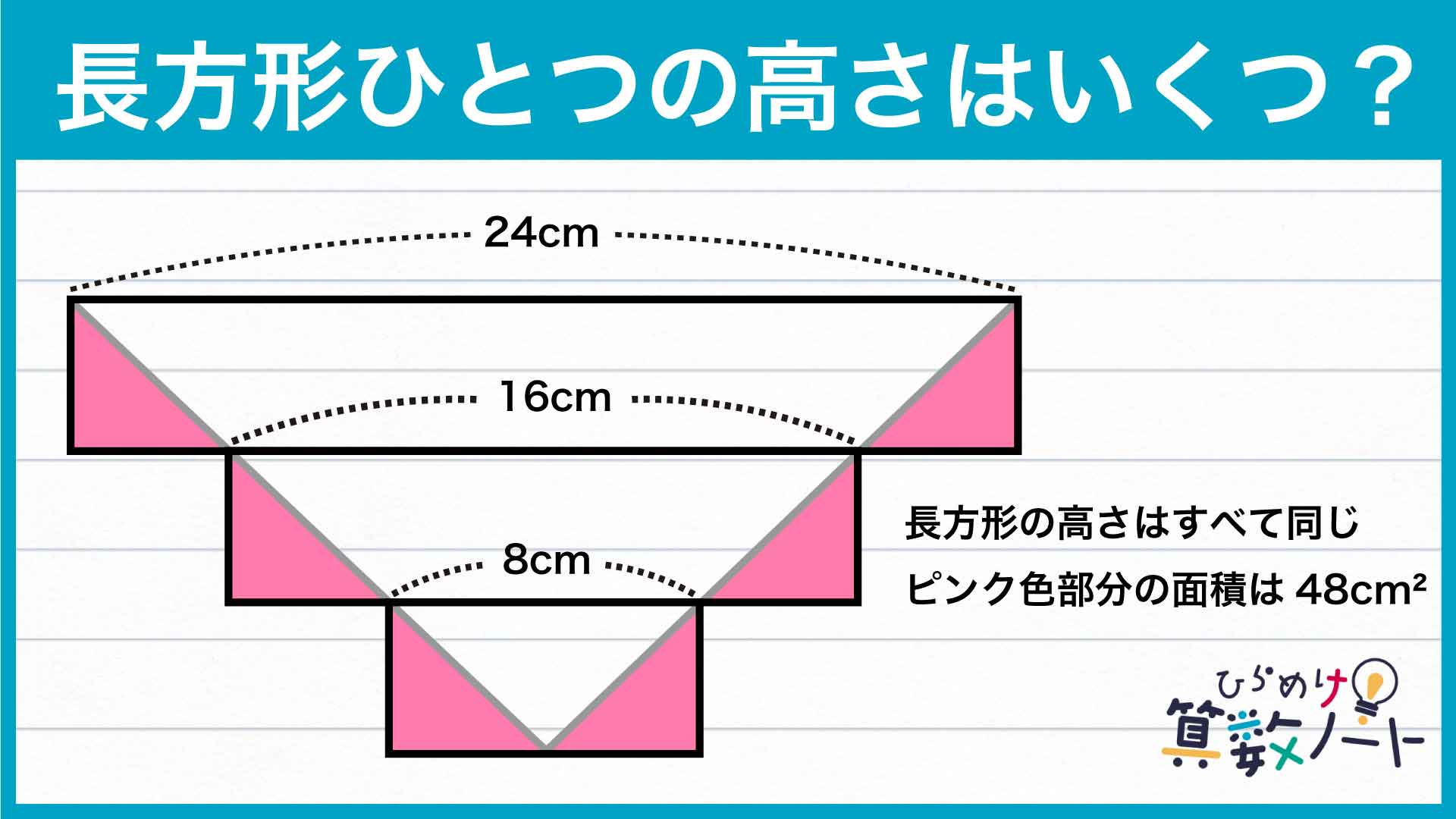
コジマです。
QRコード。カメラ付きの携帯電話やスマートフォンが普及した今、誰もが一度は読み取ったことがあるといっても過言ではないと思う。
アプリであの正方形の模様を撮影することで、コード化されたメッセージ、特にURLなどを読み取るのが基本的な使い方だろう。
しかし、時にはどうしてもスマホを取り出すことができない中でその内容を知りたいこともあるはずだ。眼というカメラはあるのだから、頭にQRコードリーダーが入っていれば……。
心配ご無用。なんと、QRコードは人力でも読めるのだ!!!やってみよう!
読む前のお約束
デッカい四角の意味

このQRコードを使ってみる(https://www.cman.jp/QRcode/ で作成)。中身は読み込んで調べてね。
QRコードの構造はこのようになっている。
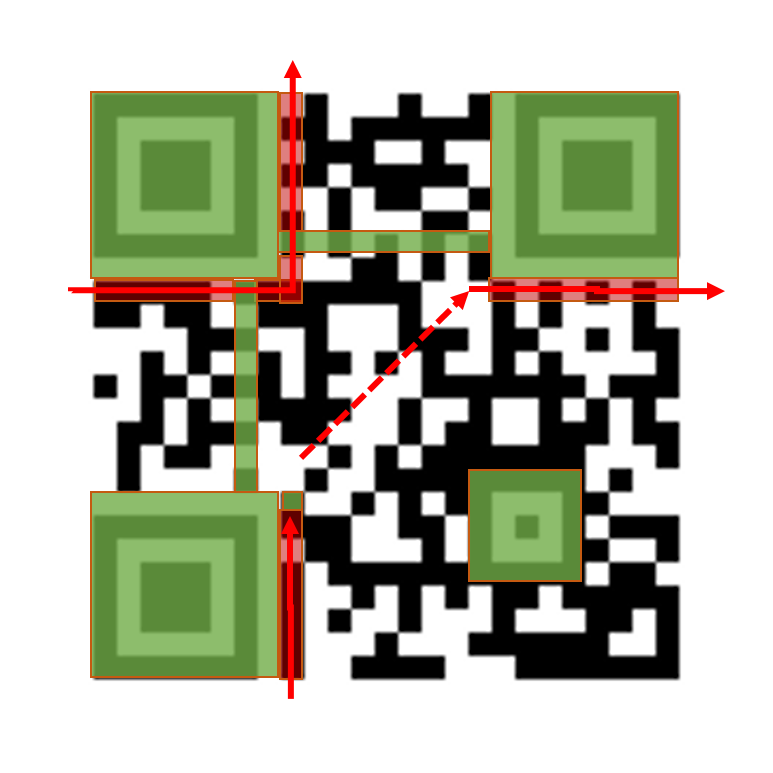 QRコードの構造。緑色部分は位置補正に必要なパターン、赤色部分はQRコードの読み取りに必要な情報(矢印の向きに読む)。
QRコードの構造。緑色部分は位置補正に必要なパターン、赤色部分はQRコードの読み取りに必要な情報(矢印の向きに読む)。緑色の部分は内容に関係ないパターンで、カメラで読み取ったときの角度の違いを補正するためのものだ。
QRコードを読むためには、まず赤色の部分を調べる必要がある。ここには「誤り訂正レベル」と、コード全体に施されたマスクの情報が書かれている。
何かと重なってても読める
「誤り訂正レベル」というのは、コードの読み取りミスを訂正する能力のことで、4段階に設定できる。レベルが高いほど読み取りの精度が悪くても(例えばQRコードの大部分が見えなくても)正しく読み取りが行えるが、その分データ量(追加する誤り訂正符号の数)が増え、コードが大きくなる。
 内容は同じで、誤り訂正レベルが最低なQRコード(左)と、最高なQRコード(右)を一部隠したもの。左は読み取れないが右は読み取れる
内容は同じで、誤り訂正レベルが最低なQRコード(左)と、最高なQRコード(右)を一部隠したもの。左は読み取れないが右は読み取れるなぜ黒ばっかりのQRコードが存在しないのか
「マスク」というのは、QRコードの黒と白をバランス良く配置するための加工のことで、8種類存在する。やたら黒が多いQRコードってあまり見たことがないと思うが、それはこのマスクをかけているからなのだ。マスクが「1」であるマスでは、元のマスの色を反転させる(0なら1、1なら0にする)。
先ほどの画像の赤い矢印の向きをなぞるようにマスを数える(緑色のマスは無視する)と15マスあるはず(矢印は2本あるが、どちらも同じ内容が書かれている)。黒いマスを1、白いマスを0とすると、このQRコードでは次のようになる。
111110110101010
この赤い部分には「101010000010010」というマスクがかかっていて、マスクをかける前のデータを求めると次のようになる。
111110110101010
101010000010010
→
010100110111000
このうち、誤り訂正レベルは最初の2マス、マスクの種類は次の3マスで表される。残りの10マスは?というと、これらは誤り訂正符号(読み取りが間違っていないか調べるためのデータ)なので、正しく読み取れるあなたには必要ない。

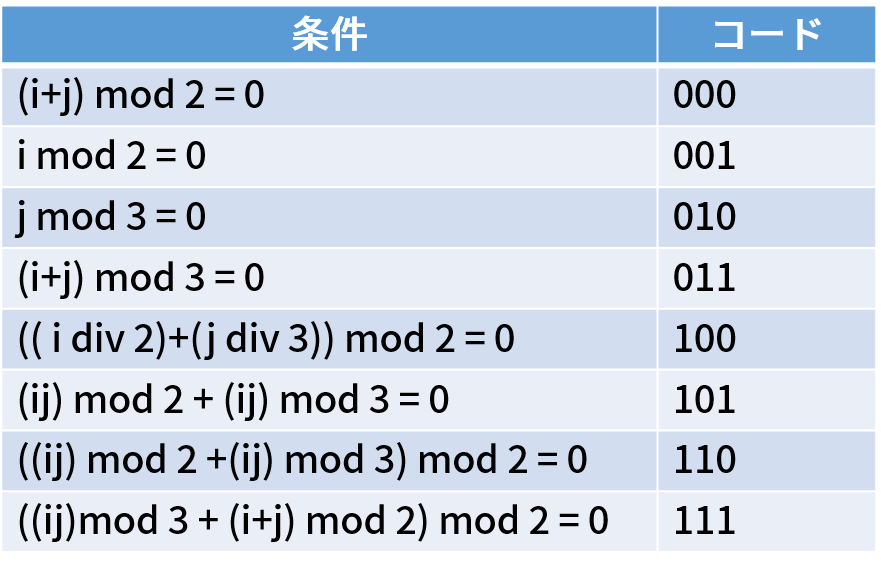
表を参照すると、このQRコードなら、誤り訂正レベルは01だから「L(約7%の誤りまで訂正可能)」、マスクの種類は010だから「j mod 3 = 0」であることがわかる。
j mod 3 = 0って何やねん……。jは、一番左の列を0としたときの列の番号を表す(一番上の行を0とした行番号がi)。j mod 3 はjを3で割った余りを表し、それが0であるマスを反転させます、というのがこのマスクの意味になる。筆者は下の方のややこしいマスクじゃなくて安心している。
わかりやすくマスクがかかるマスに色をつけてみた。この部分を反転させることに気をつけながら、肉眼でコードを読み取っていく。
 QRコード右下部分の拡大画像。マスクが施される列には青く色をつけた
QRコード右下部分の拡大画像。マスクが施される列には青く色をつけたいよいよ読んでいく
対応表を使って……
QRコードは、右下から画像に示したような順番にマスの色を調べていく。読まない領域(先ほどの画像の赤や緑の部分)に当たってしまったら、無視してそのまま次のマスを読んでしまえばいい。
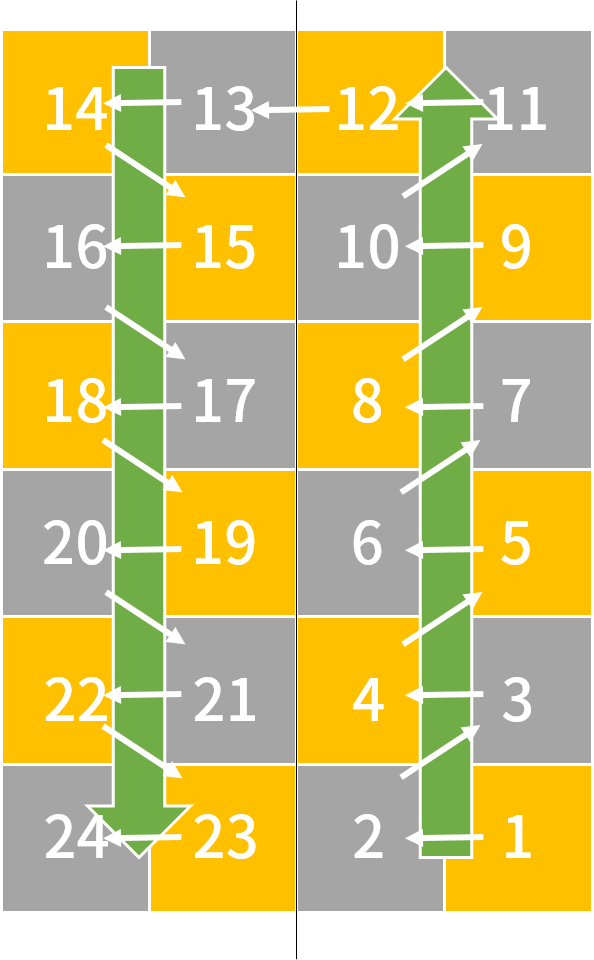
右下から最初の4マスには、どのようなデータが記録されているかが示されている。最初の4マスは「0100」なので、8ビットバイトモードで記録されているようだ。
その他、主な記録方式としては「0-9の数字の並び(0001)」、「0-9の数字、26文字のアルファベットと8種の記号(0010)」、「漢字(1000)」がある。この記事ではスペースの関係上これらの読み方については省く。
8ビットモードでサイズが25マス×25マスの場合、次の8マスはこのコードに記録されている文字数のスペースになる(文字数を記録する部分は必ずあるが、その長さは記録方式とQRコードのサイズにより変わる)。その後は実際のデータの内容になり、8マスずつ区切って読み取った8桁の2進数を、対応表から文字に置き換えていく。
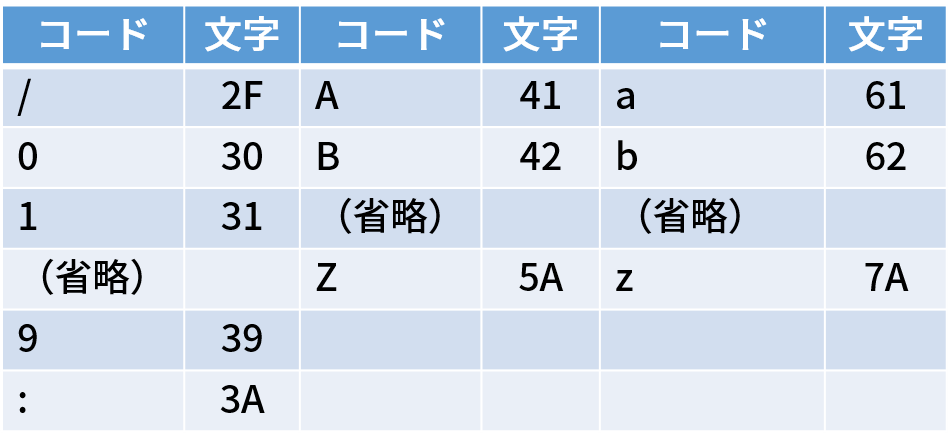 文字と2桁の16進数の変換表(一部を抜粋)。他の値に対応する文字についてはJISの基本仕様書などを参考にすること
文字と2桁の16進数の変換表(一部を抜粋)。他の値に対応する文字についてはJISの基本仕様書などを参考にすること実際にこのQRコードを右下から読んでいくと次のようになる。カッコの中は2進数を16進数に変換した結果。
0100:データモード(8ビットバイト)
00011100:文字数(28文字)
01101000(68):h
01110100(74):t
01110100(74):t
01110000(70):p
01110011(73):s
00111010(3A)::
00101111(2F):/
00101111(2F):/
……それっぽい文字列が見えてきたね?
この調子で28文字読むとこんな感じになる(左のほうは実は読み取りミスを確認するためのデータ。誤り訂正レベルが大きいとこのスペースはさらに大きくなる)。フォローミー。

まとめ
肉眼で読めるわけねーだろ!めんどくせえわ!
暗号を解読している感じの面白さがなくもないので、暇な人はやってみよう。
.jpg)