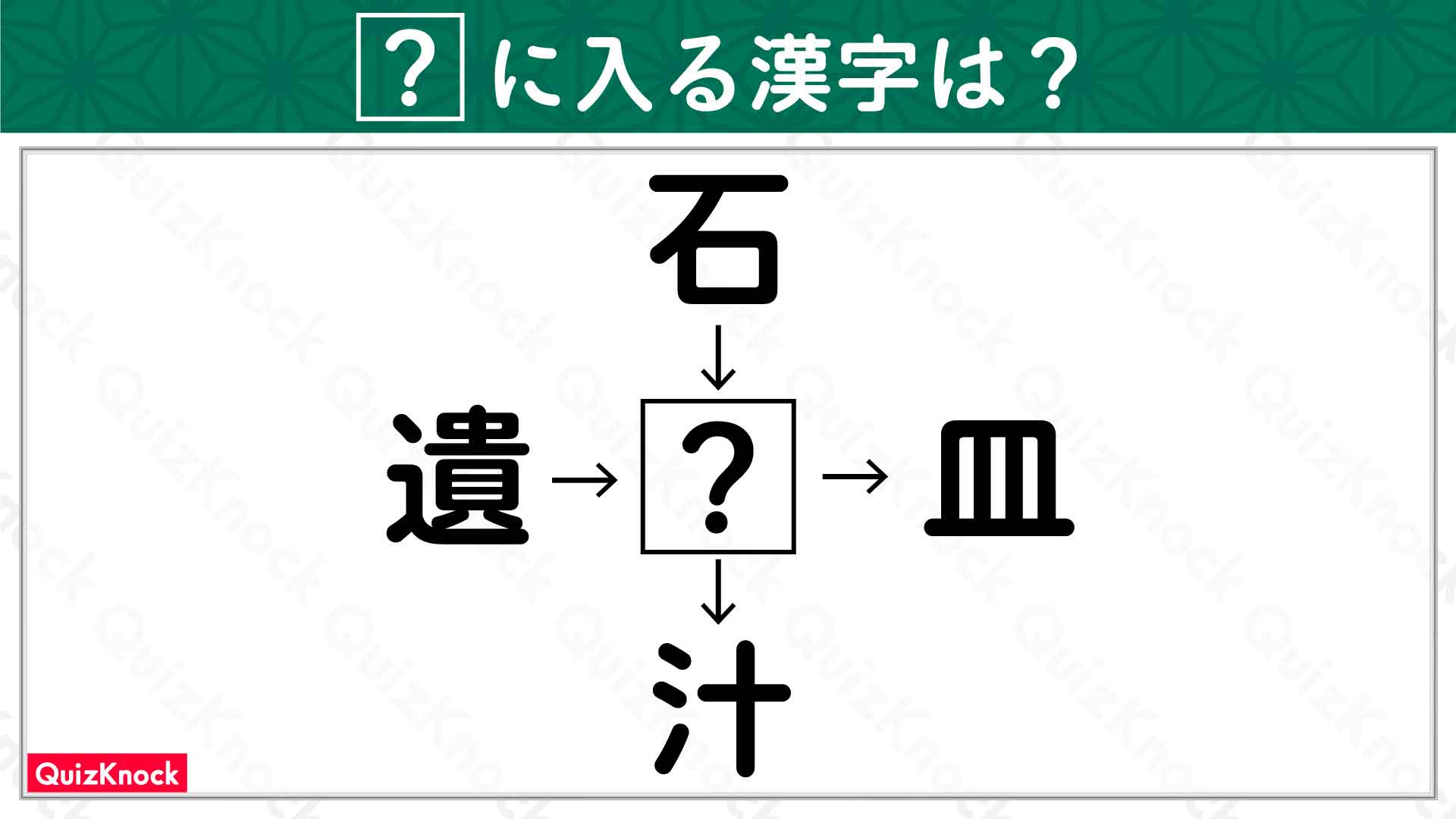
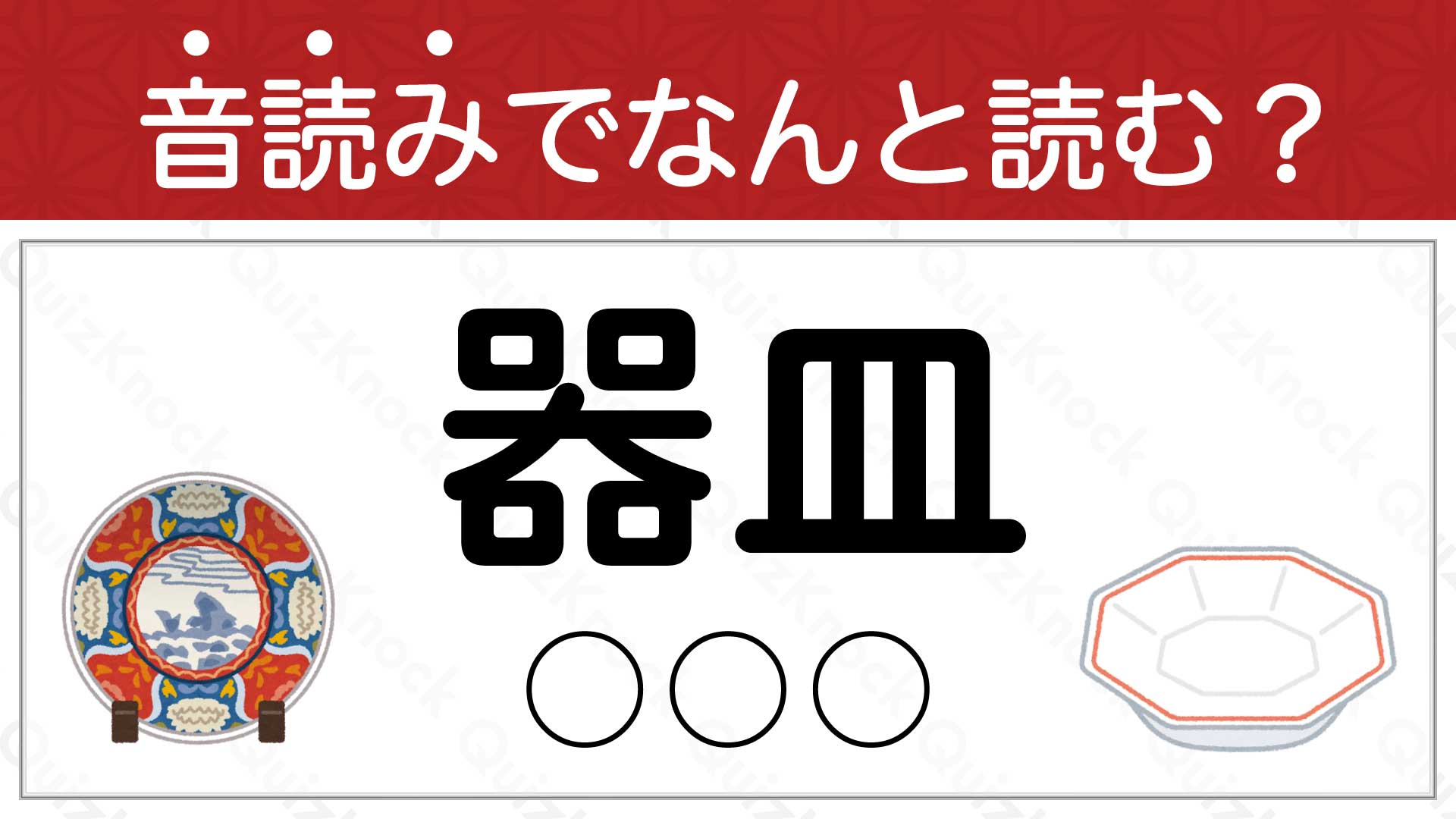
こんにちは。
この記事で囲碁AI(人工知能)を紹介したが、公開直後の年明け、謎の棋士「Master」がオンライン囲碁ソフト「野狐囲碁」に現れ、名だたるプロ棋士をバッタバッタと倒し60連勝するという事件が起こった。漫画『ヒカルの碁』から、ネット上でも「正体は藤原佐為なのでは?」などと盛り上がった。
囲碁界のほうも、今まで見たこともないような手を見せるMasterに興味津々らしい。
いま囲碁界で何が起こっているかというと,あるネット碁サイトに数日前に Master という謎のソフトが降臨し,各国の名だたるトップ棋士が挑んでいるものの人間の43連敗中らしい.棋士はというと「うおー強い!囲碁の新しい世界が見られる!」というノリで大喜びしている(観測範囲で)
— のらんぶる (@nolimbre) 2017年1月3日
https://www.facebook.com/webigojp/posts/715552808609861(オンライン囲碁ソフト「野狐囲碁」のFacebook)
http://www.j-cast.com/2017/01/06287546.html?p=all(棋士へのインタビュー)
その後、正体が例の「AlphaGo」(の改良版)であることが明かされ、その実力を世界中に再確認させた。
AlphaGoは、過去の棋譜を大量に読み込み、またAlphaGo同士で対局することにより、「ディープラーニング」によって勝つ打ち方に潜む特徴を学習している。「今までに見たことがない手」を打つということは、ディープラーニングによって人間には見抜けない戦法を見出している可能性がある。
また、AlphaGoは、「どちらがどのくらい勝っているか」を判定する仕組みを自動的に学習した。
どういうことだってばよ? というと、これまでのAI、例えば’90年代にチェスチャンピオンを破った「ディープ・ブルー」の場合などは、今までの研究に基づいて、どういう盤面が「勝てそう」なのかというのをチマチマ打ち込んでいたのだが、AlphaGoはそのような作業を行っていないらしい。
極端な話、囲碁の勝ち方が分からなくても囲碁ソフトが作れてしまうのである。
「ディープラーニング」、今回の件も含め、AIブームでよく聞くようになった言葉である。が、「何かスゴいらしい」くらいの認識しかない人が大半ではないだろうか。また、「囲碁のプロを負かすほどのAIなんだから得体の知れない黒魔術とか使ってんじゃないの?」という方も多かろう。
学科専門の講義で人工知能を学んだ(単位は落としたけど)立場から言わせてもらうと、ディープラーニングは理屈としては意外に単純だ。
単位は落としたけど複数の文献を読んでAlphaGoの論文も目を通して勉強し直しました。許してください。
この記事を読んで、どうしてAlphaGoが見たこともない手で勝てるのか?とか、勝ち方を勝手に学べるのか?が1割くらい分かると、これから味方にするにしても敵に回すにしても(ゼロよりは)役立つと思う。
人工知能や機械学習の基本は、「データを入力したときに、条件に当てはまるものに対してだけ1となる」ような関数を作ることである。
最初期は、「入力それぞれに対して重要度・影響力の大きさを示す値(「パラメータ」や「重さ」と呼ぶ)を決め、入力との積を足し合わせた値によって判定を行う」という、単純な関数が考えられていた(パーセプトロンという)。
囲碁で考えよう。仮に図の赤い点線で囲まれた目がオセロの角くらい重要であるとして(実際はそんなことはない)、局面の強さを判定するパーセプトロンを考える。
黒石がある目を1、それ以外を0と表し、赤い範囲の目の重要度を1、それ以外の重要度を0とすれば、計算結果が2となる上の盤面は評価され、0である下の盤面は評価されない。
もし、赤枠の中でも特に右下が重要だということが分かれば、その他の3目の重要度を0.5とかに減らせばよいし、他の目が重要だとなればその重要度を増やす。
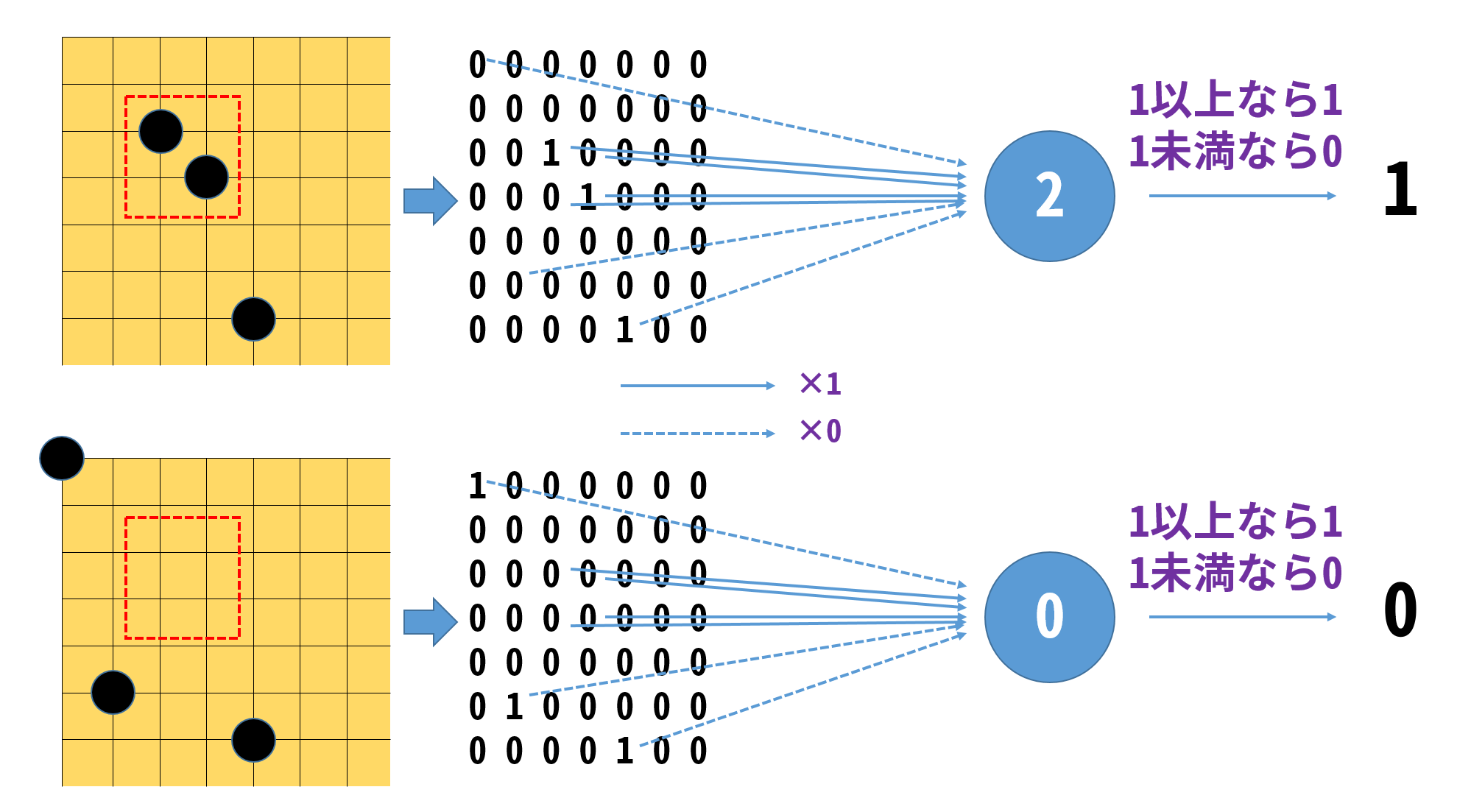 局面の強さを判定するパーセプトロンの図。
局面の強さを判定するパーセプトロンの図。パーセプトロンは、理屈もパラメータを決める方法も簡単なのだが、パーセプトロンではどう頑張っても判定できないような問題も存在し、単純なパーセプトロンじゃ単純な判定しかできないよということが数学的にも証明されたため、AIは一度研究者から見捨てられてしまう。
が、AIが斜陽の時代に研究を続けたエラい人のおかげで、単純に掛けて足すだけではダメでも、このような方法で値をいくつか作り(OKなら1、NGなら0)、それらの値をさらにパーセプトロンで判定すると、複雑な問題でも解けることが分かった。
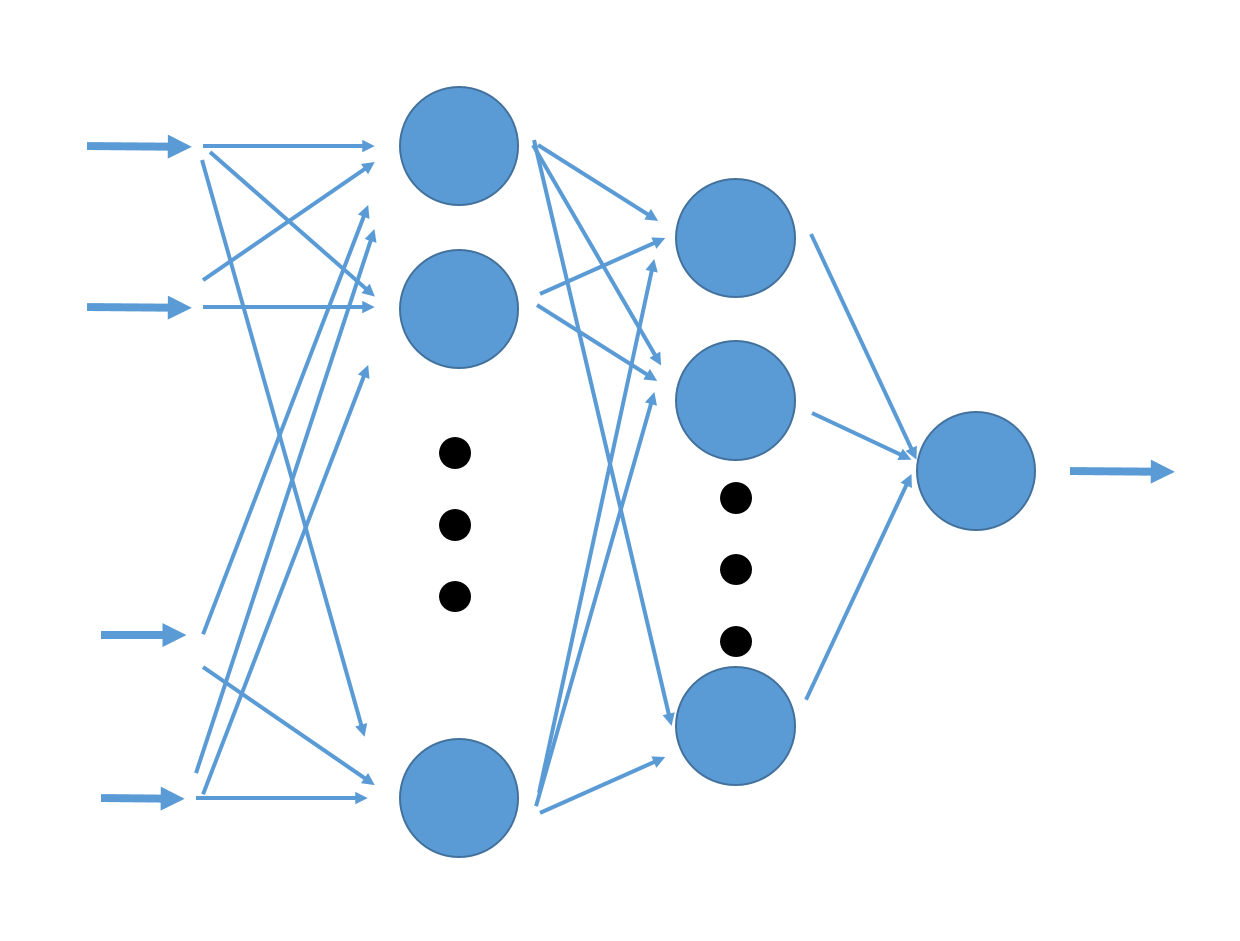 パーセプトロンを並べ、多段構造にした図。
パーセプトロンを並べ、多段構造にした図。なぜ複雑な問題が解けるようになるのか?というと、1段目のパーセプトロンによって簡単な特徴が抜き出され、2段目でそうした特徴を総合して判定している、と考えれば納得がいく。
特徴から特徴を抜き出すとより複雑な特徴が得られる、という発想の下、パーセプトロンを10段、20段と何段も重ねて行う機械学習が、いわゆるディープラーニングなのである(実際は色々な工夫を加えて学習を行えるようにしている)。
ディープラーニングは、結果から逆算して学習していくので、よりよい結果に直結した学習結果が得られる。それが囲碁に発揮された結果、人間が千年以上かけても気付けなかった勝ち筋が解き明かされようとしている。ロマンあふれるAlphaGo。
また、ディープラーニングはあくまでもデータの統計的な特徴を調べているに過ぎない。従って同じ手法で様々な分野のビッグデータを解析でき、その中に専門家の手は介在しない(実際はデータの前処理などで専門知識が必要だが)。
ディープラーニングによって得られる最大の利益は、専門知識に基づいた手作業を大きく削減できるようになったことかもしれない。
実はここまでで説明したことは'80年代には知られていたのだが、ディープラーニングの成果が現れ始めたのは2010年に入ってからだ。
というのも、複雑なことができるAIを構成するには、膨大なデータと膨大な計算を行える計算機が必要で、理屈ではできてもそれを実現できる環境が整わなかったのである。インターネットからデータをかき集めることができるようになり、また計算機の機能が向上したことが、AI研究の進歩に大きく寄与している。
ディープラーニングのまとめ
- 特徴から特徴を抜き出す、を繰り返して難しい問題を解く
- 隠された特徴が見抜ける
- データがあれば専門知識は不要
- 膨大なデータと計算が必要
これだけ覚えて、レッツ知ったかぶり!
.jpg)